

Kínai, mesterséges intelligenciával foglalkozó kutatók elértek valamit, amiről sokan azt hitték, hogy fényévekre van tőlünk. Egy ingyenes, nyílt forráskódú mesterséges intelligenciamodell, amely képes elérni vagy meghaladni az OpenAI legfejlettebb rendszereinek teljesítményét. Ami még figyelemre méltóbbá teszi ezt, az az, ahogyan ezt a kutatók elérték. Hagyták, hogy a mesterséges intelligencia próbálgatással és tévedéssel tanítsa magát, hasonlóan ahhoz, ahogyan az emberek tanulnak. A DeepSeek-R1-Zero, egy magas skálán működő megerősítő tanulás (RL) révén, előzetes lépésként felügyelt finomhangolás (SFT) nélkül betanított modell figyelemre méltó érvelési képességeket mutat.
A „megerősítéses tanulás” egy olyan módszer, amelyben egy modellt jutalmaznak a jó döntésekért és büntetnek a rossz döntésekért, anélkül, hogy a modell tudná melyik melyik. Egy sor döntés után aztán a modell megtanulja, hogy olyan utat kövessen, amelyet ezek az eredmények megerősítettek.
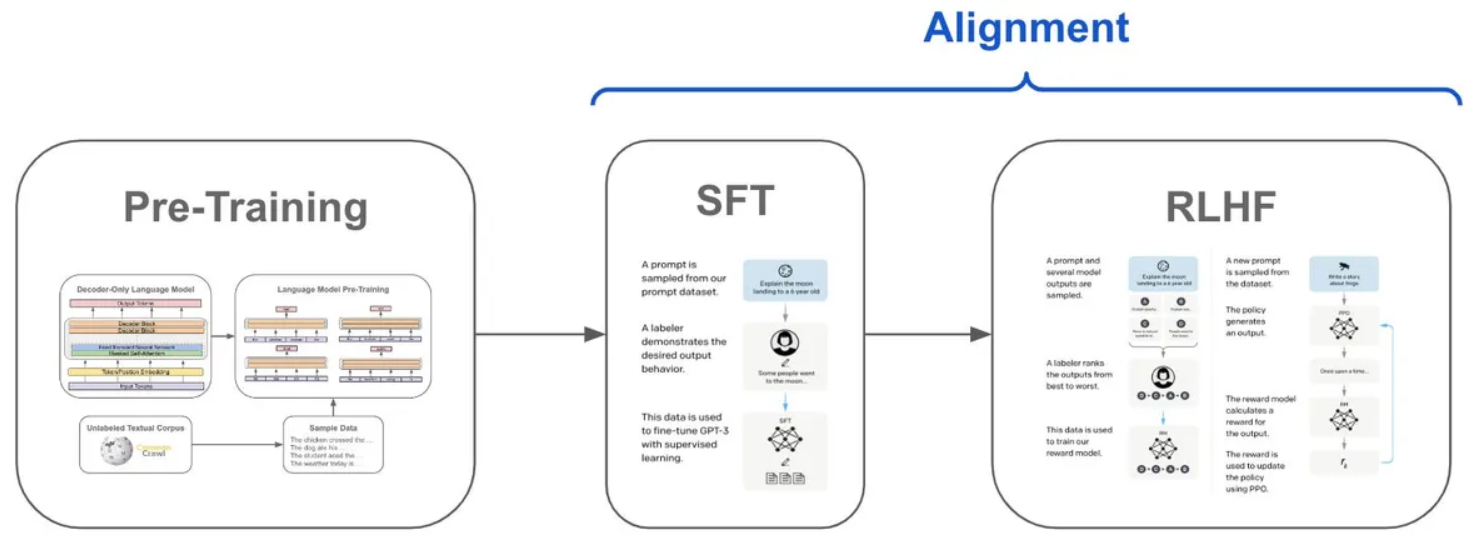
Kezdetben, a felügyelt finomhangolási fázisban egy csapat közli a modellel a kívánt kimenetet, így adva neki kontextust, hogy tudja, mi a jó és mi nem. Ez vezet a következő fázishoz, a megerősítéses tanuláshoz, amelyben a modell különböző kimeneteket ad, és az emberek rangsorolják a legjobbakat. A folyamatot addig ismételjük újra és újra, amíg a modell nem tudja, hogyan kell következetesen kielégítő eredményeket szolgáltatni. A DeepSeek R1 a mesterséges intelligencia fejlesztésének egyik csúcsragadózója. Mivel az embernek minimális szerepe van a képzésében.
Már a DeepSeek működése is lenyűgöző
Más modellekkel ellentétben, amelyeket hatalmas mennyiségű felügyelt adatom működtetnek, a DeepSeek R1 elsősorban mechanikus megerősítő tanulással tanul. Lényegében kísérletezéssel és visszajelzéssel találja ki a dolgokat. A modell még olyan kifinomult képességeket is kifejlesztett, mint az önellenőrzés és a reflexió, anélkül, hogy kifejezetten erre programozták volna. Ahogy a modell végigment a betanítási folyamaton, természetesen megtanult több gondolkodási időt szánni az összetett problémákra, és kifejlesztette azt a képességet, hogy saját hibáit is észrevegye. A kutatók kiemeltek egy olyan aha pillanatot, amikor a modell megtanulta újraértékelni a problémák eredeti megközelítését. Pedig erre nem volt programozva.
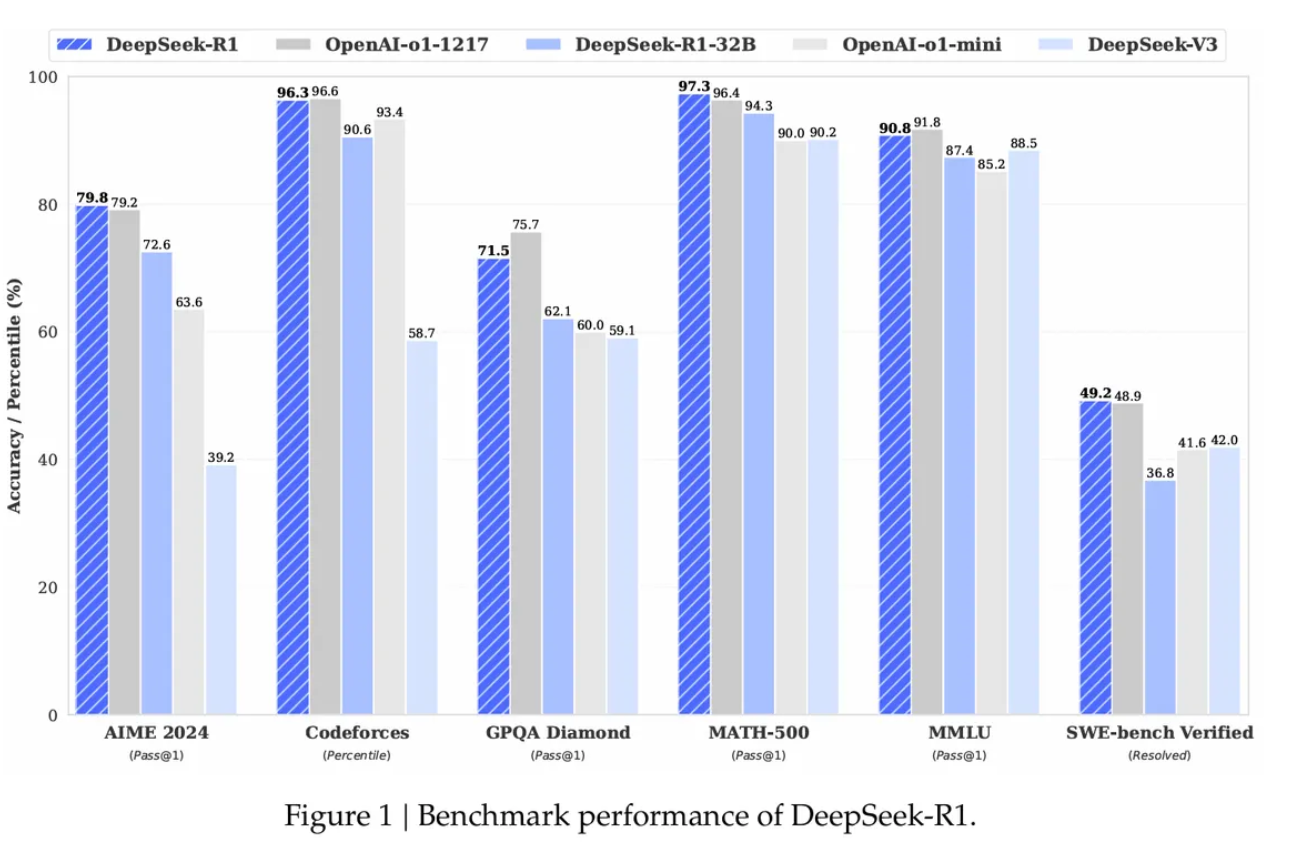
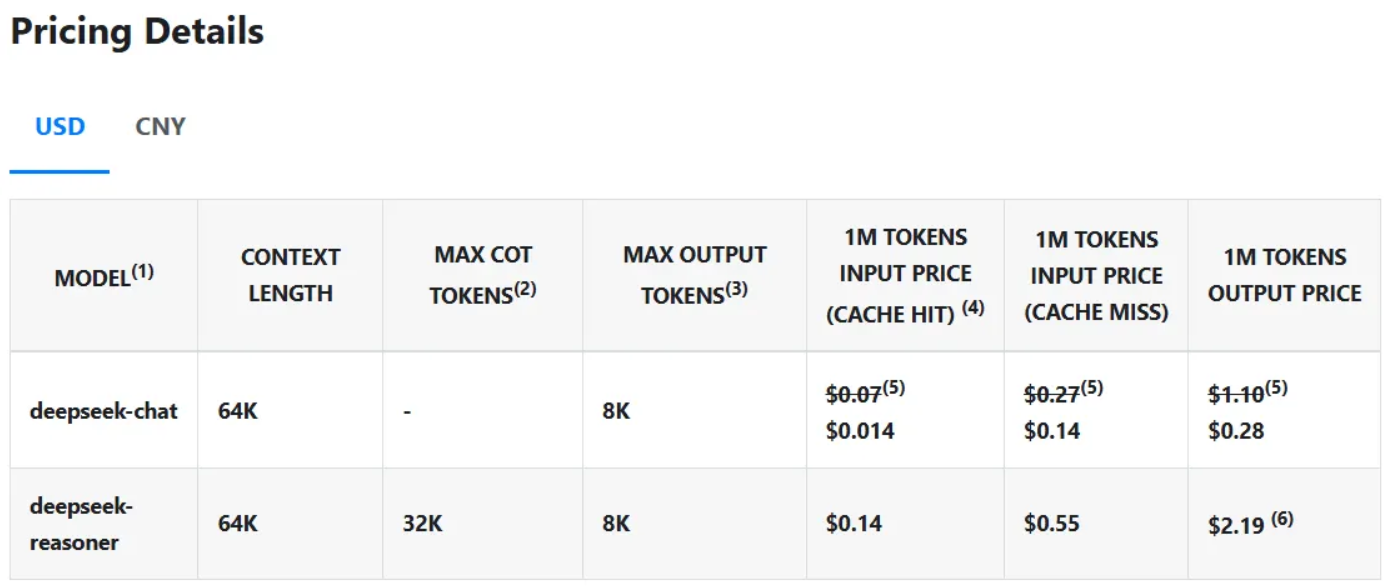
A teljesítményszámok lenyűgözőek. Az AIME 2024 matematikai indikátoron a DeepSeek R1 79,8%-os sikerességi arányt ért el, ezzel felülmúlta az OpenAI o1 következtetési modelljét. A szabványosított kódolási teszteken szakértői szintű teljesítményt mutatott, a Codeforces-on 2029 Elo értéket ért el, és az emberi versenytársak 96,3%-át felülmúlta. Ami azonban igazán kiemeli a DeepSeek R1-et a többi közül, az a költsége. A modell egymillió tokenenként mindössze 0,14 dollárért futtatja a lekérdezéseket, szemben az OpenAI 7,50 dolláros árával, ami 98%-kal olcsóbb. A szabadalmaztatott modellekkel ellentétben a DeepSeek R1 kódja és képzési módszerei teljesen nyílt forráskódúak az MIT licenc alapján. Azaz bárki használhatja és módosíthatja is a modellt.
A visszhangok
Az eredmény komoly visszhangot váltott ki. Az Nvidia vezető kutatója, Dr. Jim Fan adta talán a legérdekesebb kommentet. Ő arról írt, hogy, hogy most egy olyan periódus van, ahol egy nem amerikai vállalat tartja életben az OpenAI eredeti küldetését – a valóban nyílt forrású kutatást a határok eléréséhez. Awni Hannun, az Apple kutatója megemlítette, hogy az emberek a modell egyszerűsített verzióját lokálisan futtathatják a Mac-jeiken.
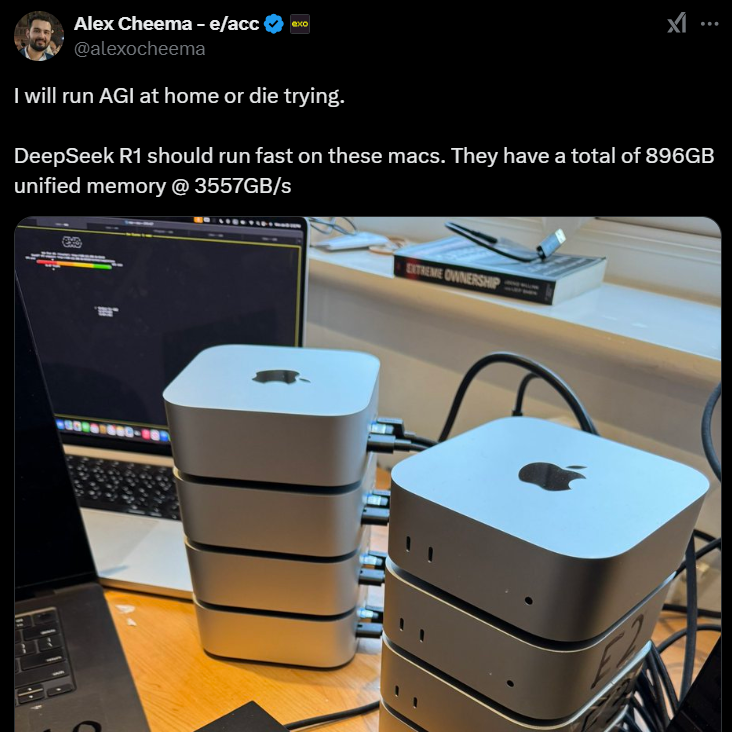
Az Apple készülékei hagyományosan gyengék voltak a mesterséges intelligencia terén, mivel nem kompatibilisek az Nvidia CUDA szoftverével, de úgy tűnik, ez most változik. Alex Cheema AI-kutató például képes volt a teljes modell futtatására, miután 8 Apple Mac Mini egység együttes futtatásának erejét használta fel. A legérdekesebb reakciókat azonban az váltotta ki, hogy a nyílt forráskódú iparág mennyire közel áll a szabadalmaztatott modellekhez. És hogy ez a fejlemény milyen hatással lehet az OpenAI-ra, mint az érvelő mesterséges intelligencia modellek vezetőjére.
A Stability AI alapítója, Emad Mostaque provokatív álláspontot képviselt, azt sugallva, hogy ez az eredmény nyomást gyakorol a jobban finanszírozott versenytársakra. És az iparágban nincs egyedül ezzel az állásponttal. A legtöbben káros hatásként értelmezik a DeepSeek teljesítményét. Mintha valaki Ferrarit töredékáron kezdene el, szinte ingyen osztogatni.
Egy teszt
Egy tesztben meg is próbálták felmérni a DeepSeek képességeit. Megkérdezték a modelleket, hogy mondják meg hány R betű van az eper szóban (értelemszerűen angolul). A modellek általában azért küzdenek a helyes válasz megadásával, mert nem szavakkal dolgoznak – hanem tokenekkel, a fogalmak digitális reprezentációival. A GPT-4o kudarcot vallott, az OpenAI o1 sikerrel járt – és a DeepSeek R1 is. Az o1 nagyjából csak megadta a választ, a DeepSeek viszont hosszas érvelési folyamattal, szlengeket használva írta meg válaszát. A modell végül eljutott a helyes eredményre, de sok időt töltött érveléssel és a tokenek kiadásával. Tipikus árképzési körülmények között ez hátrány lenne.
De a dolgok jelenlegi állása szerint sokkal több tokent tud kiadni, mint az OpenAI o1, és még mindig versenyképes. Akit érdekel a modell helyi futtatása, letöltheti a Githubról vagy a Hugging Face-ről. A felhasználók letölthetik, futtathatják, finomhangolással különböző szakterületekhez igazíthatják. Ha pedig online szeretné kipróbálni valaki a modellt, látogasson el a Hugging Chat vagy a DeepSeek webportáljára, amely jó alternatívája a ChatGPT-nek. Rákkutatásban még nem biztos, hogy segíthet, de lehet, hogy nem csak a millliárdosok használhatják az AI lehetőségeit.












